Output Settings¶
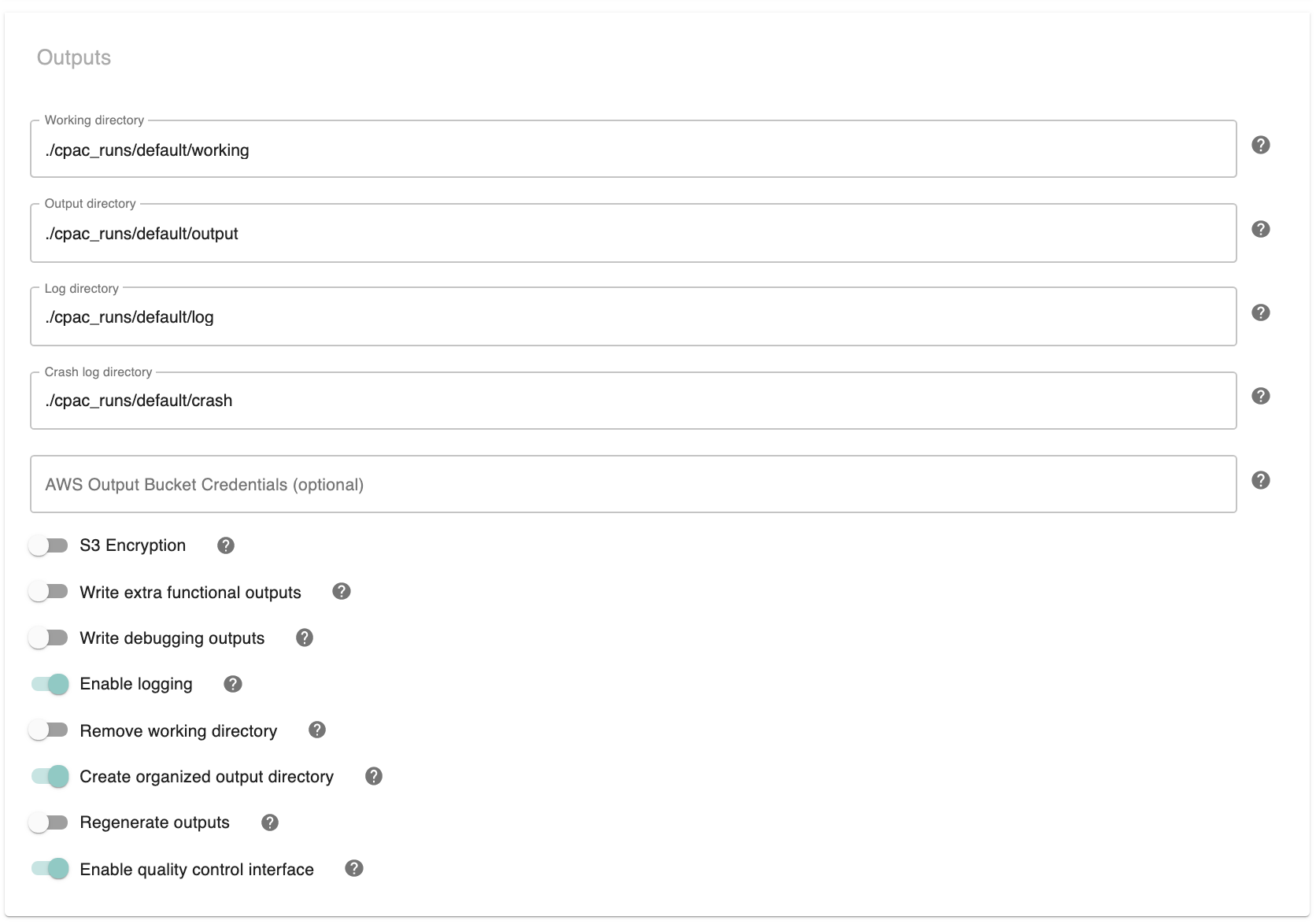
Working Directory - [path]: Directory where CPAC should store temporary and intermediate files. Path should not contain spaces.
Output Directory - [path]: Directory where CPAC should place processed data. This can also be an S3 bucket path prepended with ‘s3://’. Path should not contain spaces.
Log Directory - [path]: Directory where CPAC should place run logs. Path should not contain spaces.
Crash Log Directory - [path]: Directory where CPAC should write crash logs. Path should not contain spaces.
AWS Output Bucket Credentials (optional) - [path]: If setting the Output Directory to an S3 bucket, insert the path to your AWS credentials file here.,
S3 Encryption - [On, Off]: Enable server-side 256-AES encryption on data to the S3 bucket,
Write Extra Functional Outputs - [On, Off]: Include extra versions and intermediate steps of functional preprocessing in the output directory.
Write Debugging Outputs - [On, Off]: Include extra outputs in the output directory that may be of interest when more information about intermediate steps is needed.
Enable logging - [On, Off]: Whether to write log details of the pipeline. run to the logging files..
Remove Working Directory [On, Off]: Deletes the contents of the Working Directory after running. This saves disk space, but any additional preprocessing or analysis will have to be completely re-run.)
Create organized output directory - [On, Off]: Create a simplified version of the output directory.
Regenerate Outputs - [On, Off]: Uses the contents of the working directory to regenerate all outputs and their symbolic links. Requires an intact working directory from a previous C-PAC run.
Enable Quality Control Interface - [On, Off]: Generate quality control pages containing preprocessing and derivative outputs.
Configuration Without the GUI¶
The following nested key/value pairs will be set to these defaults if not defined in your pipeline configuration YAML.
pipeline_setup:
# Name for this pipeline configuration - useful for identification.
pipeline_name: cpac-default-pipeline
output_directory:
# Directory where C-PAC should write out processed data, logs, and crash reports.
# - If running in a container (Singularity/Docker), you can simply set this to an arbitrary
# name like '/output', and then map (-B/-v) your desired output directory to that label.
# - If running outside a container, this should be a full path to a directory.
path: /output
# (Optional) Path to a BIDS-Derivatives directory that already has outputs.
# - This option is intended to ingress already-existing resources from an output
# directory without writing new outputs back into the same directory.
# - If provided, C-PAC will ingress the already-computed outputs from this directory and
# continue the pipeline from where they leave off.
# - If left as 'None', C-PAC will ingress any already-computed outputs from the
# output directory you provide above in 'path' instead, the default behavior.
source_outputs_dir: None
# Set to True to make C-PAC ingress the outputs from the primary output directory if they
# exist, even if a source_outputs_dir is provided
# - Setting to False will pull from source_outputs_dir every time, over-writing any
# calculated outputs in the main output directory
# - C-PAC will still pull from source_outputs_dir if the main output directory is
# empty, however
pull_source_once: True
# Include extra versions and intermediate steps of functional preprocessing in the output directory.
write_func_outputs: False
# Include extra outputs in the output directory that may be of interest when more information is needed.
write_debugging_outputs: False
# Output directory format and structure.
# Options: default, ndmg
output_tree: "default"
# Quality control outputs
quality_control:
# Generate quality control pages containing preprocessing and derivative outputs.
generate_quality_control_images: True
# Generate eXtensible Connectivity Pipeline-style quality control files
generate_xcpqc_files: False
working_directory:
# Directory where C-PAC should store temporary and intermediate files.
# - This directory must be saved if you wish to re-run your pipeline from where you left off (if not completed).
# - NOTE: As it stores all intermediate files, this directory can grow to become very
# large, especially for data with a large amount of TRs.
# - If running in a container (Singularity/Docker), you can simply set this to an arbitrary
# name like '/work', and then map (-B/-v) your desired output directory to that label.
# - If running outside a container, this should be a full path to a directory.
# - This can be written to '/tmp' if you do not intend to save your working directory.
path: /tmp
# Deletes the contents of the Working Directory after running.
# This saves disk space, but any additional preprocessing or analysis will have to be completely re-run.
remove_working_dir: True
log_directory:
# Whether to write log details of the pipeline run to the logging files.
run_logging: True
path: /logs
crash_log_directory:
# Directory where CPAC should write crash logs.
path: /crash
Amazon-AWS:
# If setting the 'Output Directory' to an S3 bucket, insert the path to your AWS credentials file here.
aws_output_bucket_credentials:
# Enable server-side 256-AES encryption on data to the S3 bucket
s3_encryption: False
Debugging:
# Verbose developer messages.
verbose: Off